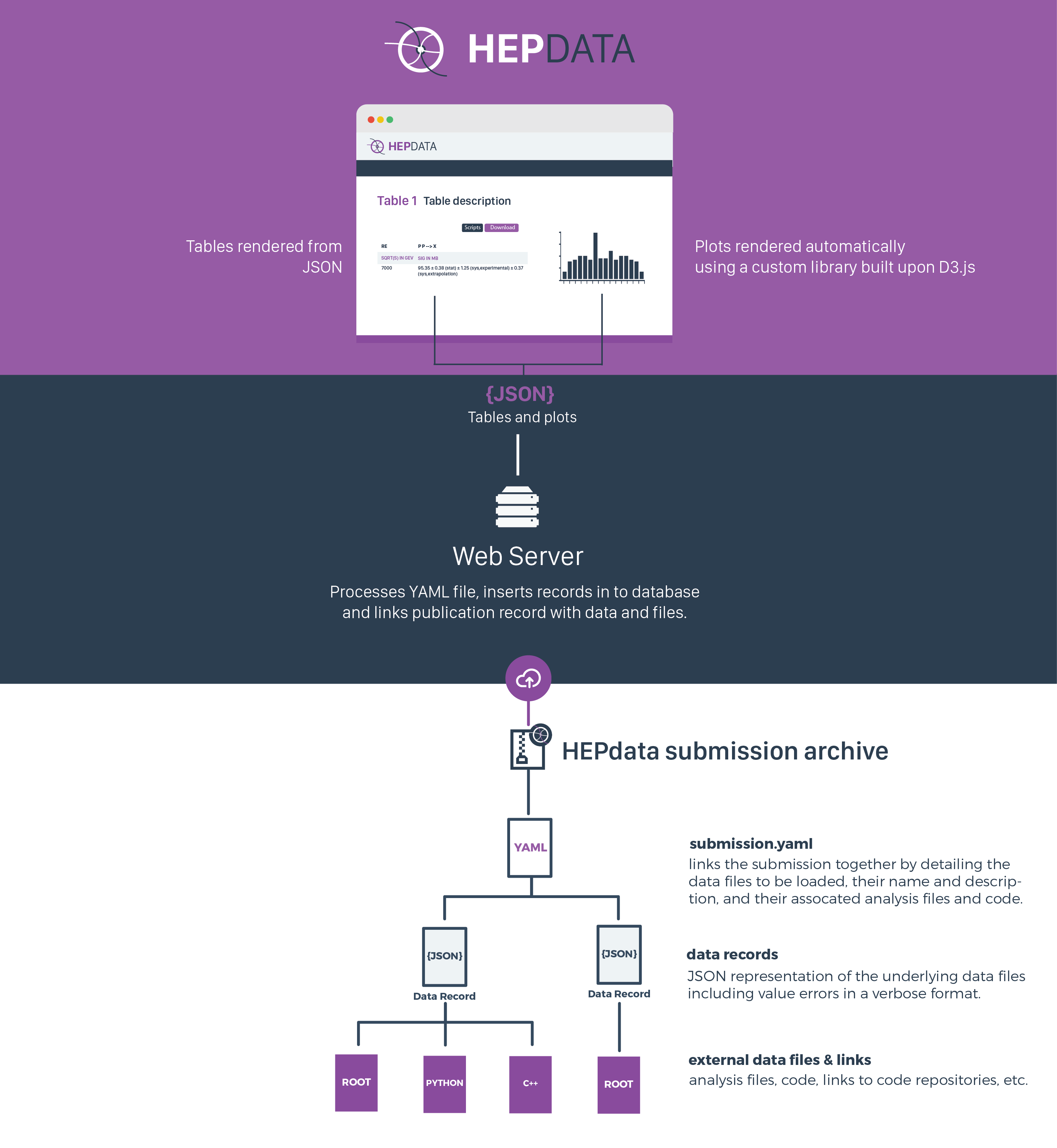
Introduction¶
HEPData submission will largely involve the
upload of archive files (.zip, .tar, .tar.gz, .tgz)
containing a number of YAML files together with
possible auxiliary files of any format. Basic introductions to YAML
can easily be found via Google,
for example, Wikipedia or
Learn X in Y minutes.
It is also possible to upload a single text file with extension .oldhepdata (see
sample.oldhepdata) containing
the “input” format that was used for data submissions from the old
HepData site (before 2017). Upon upload, the .oldhepdata file will be automatically
converted to the new YAML format.
However, this method is not recommended and it may eventually be phased out.
The main file for a submission is the submission.yaml file. This links together all the data tables into one submission and specifies auxiliary files such as scripts used to create the data, ROOT files, or even links to repositories like GitHub/GitLab/Bitbucket/Zenodo etc. for more substantial pieces of code.
Publication information such as the paper title, authors and abstract, or the journal reference and DOI, is pulled from the corresponding INSPIRE record, therefore it does not need to be included in the submission.yaml file. The publication information is added to the HEPData record when a Coordinator first attaches the INSPIRE ID, and it is updated when a HEPData record is finalised by a Coordinator. After a HEPData record has been finalised, publication information from INSPIRE is automatically updated, for example, if a preprint is later published in a journal.
The data files for each table, in either YAML or JSON format, specify the data points in terms of independent and dependent variables.
See also Section 6 of arXiv:1704.05473 for an overview of the submission process.